OCR Xpress for Node.js is an SDK designed for document recognition applications. OCR Xpress for Node.js performs the task of recognizing printed characters in a digital image. The digital image can be captured into an uncompressed Bitmap file (BMP) using scanners, cameras, or fax machines. Once the image is loaded, the application has three processing choices:
- Generate a searchable PDF file.
- Generate a searchable text file
- Create a hierarchically structured data model of the image.
Figure 1 shows how OCR Xpress for Node.js is laid out.
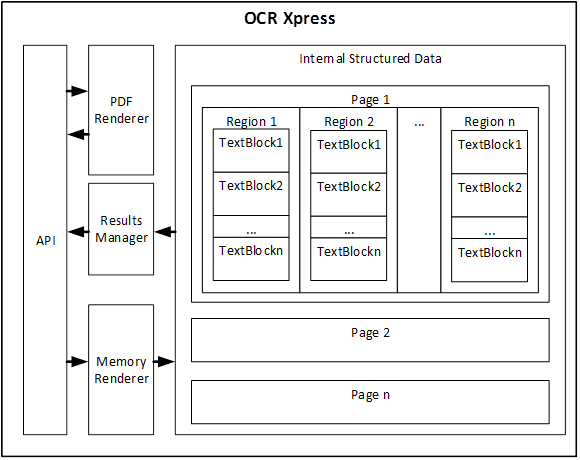
Figure 1: OCR Xpress for Node.js Model
The API manages three forms of interaction.
- To generate a PDF file, the API will use the PDF Renderer. In the PDF Renderer an OCR operation will be performed on the image to generate text data. The resultant text data is then used to build a PDF file and finally the image is overlaid on top of the text to produce a searchable PDF file. This is all done with a single API call.
- Call recognize(), setting an input parameter of 'format' to a value of 'pdf'.
- To generate a text file, the API will use the Memory Rendered and the Internal Structured Data to extract the text data for the image. Once again, this process is accomplished with just one API call.
- Call recognize(), setting an input parameter of 'format' to a value of 'text'.
- The third form of API interaction is for applications that need to dig deeper into the spatial relationships of the text data in the image. For example, if an application needs to calculate how far a certain word in one text line is from another word in another text line, it would use this level of API interaction to retrieve the areas/locations of the words in question.
OCR Xpress for Node.js constructs and maintains a hierarchical model of the OCR results. Every character found in the image is related to every other character in the image with the hierarchically structured data model. The Internal Structured Data block in Figure 1 represents this hierarchical structured data model. Note that the model is organized into pages, regions, and text blocks. Figure 2 shows how text blocks are organized even further into text lines, words, and characters.

Figure 2: Organization of text lines, words, and characters in a text block
An application has access to all this structured data via the Results Manager. The Results Manager and Get Functions topic goes into the details of how to access and use this data. In order to access the Internal Structured Data, the application just has to make a single call to the API.
- Call recognize(). When passing in a callback function, the second argument is a Document object. The application would then use the returned Document object’s get properties to interrogate the Internal Structured Data and to retrieve data from it.
Once the Internal Structured Data is constructed, it remains persistent until the Document moves out of scope or is set to null and deleted by the garbage collector.
